How our platform
makes a difference
Our automated technology advances the application of precision medicine and allows our partners to provide complete evidence-based recommendations.
How it works
Weekly Data Import
The Data Lake
MolecularMatch regularly imports over 50 clinical and molecular data sources into our Data Lake.


Ontological Data Model
Making Sense of Collected Data
Native sources are normalized into a common schema, resulting in MolecularMatch’s Clinical Data Model. The data is transformed and augmented by processing it using a molecular and biomedical logic engine that recognizes over 50M clinical and molecular terms.
AI-Powered Curation
Comprehending unstructured documents
MolecularMatch’s Classical NLP and Deep Learning Training Models, in conjunction with Human-In-The-Loop Curation Platform, comprehend clinical and molecular terminology.
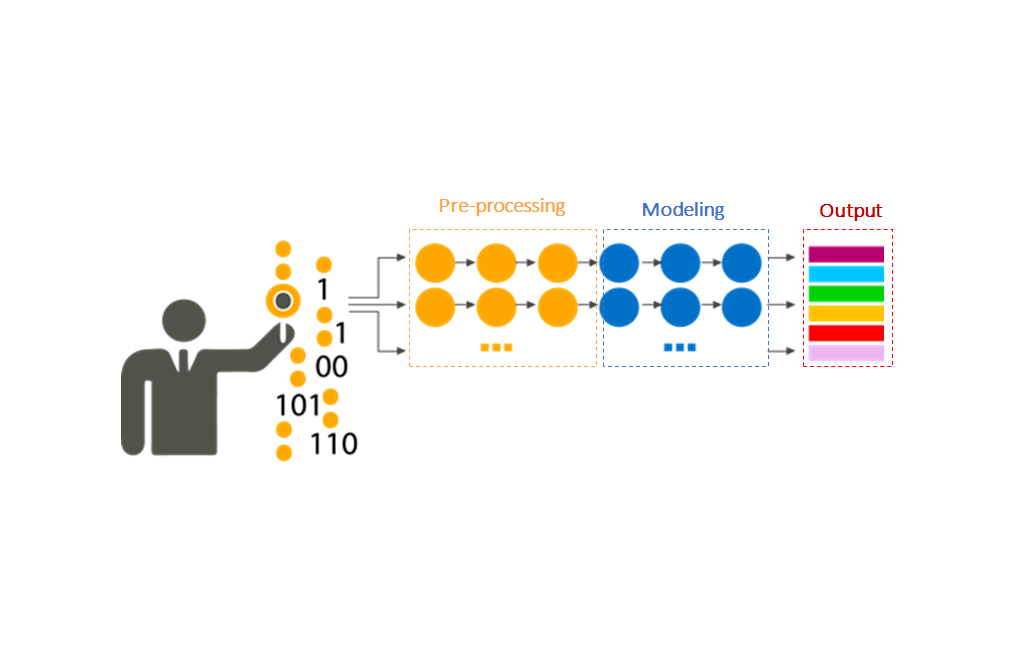

Concepts Map & Search Engine
Data Enrichment and Concept Tagging
The Culmination of this AI-Powered, Human-In-The-Loop Curation Process is the MolecularMatch Clinical Concepts Map and Search Engine.
Data-as-a-Service (DaaS)
The MolecularMatch Software Development Kit (SDK)
MolecularMatch’s Clinical Search Engine delivers Clinical and Molecular Informatics results through high-performance, cloud-based data servers via a RESTful API, as well as support for Java and Python (more languages to come) in our SDK.
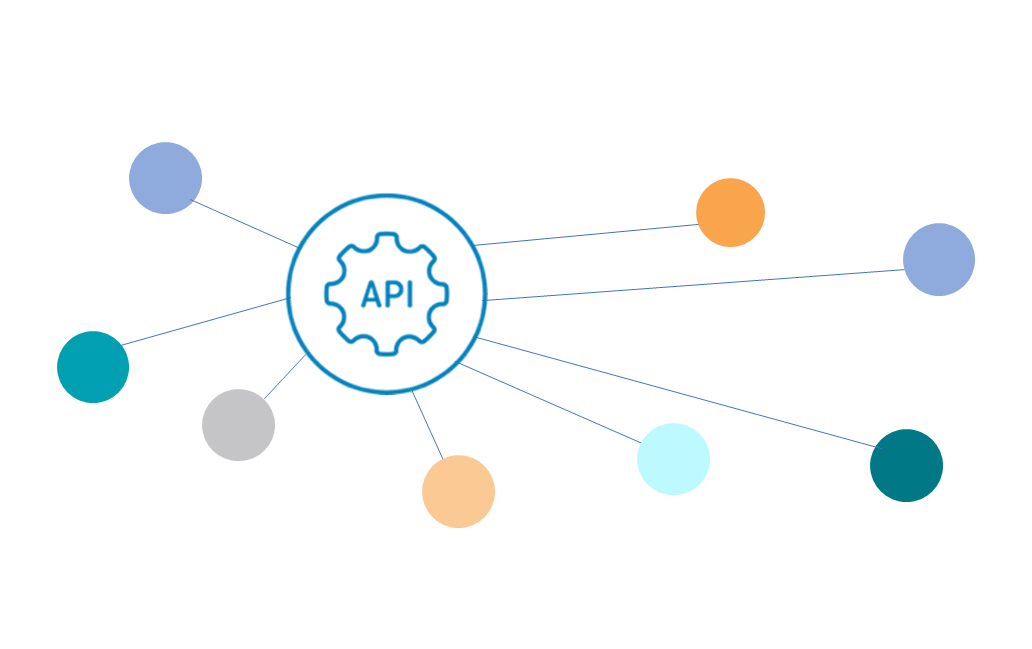
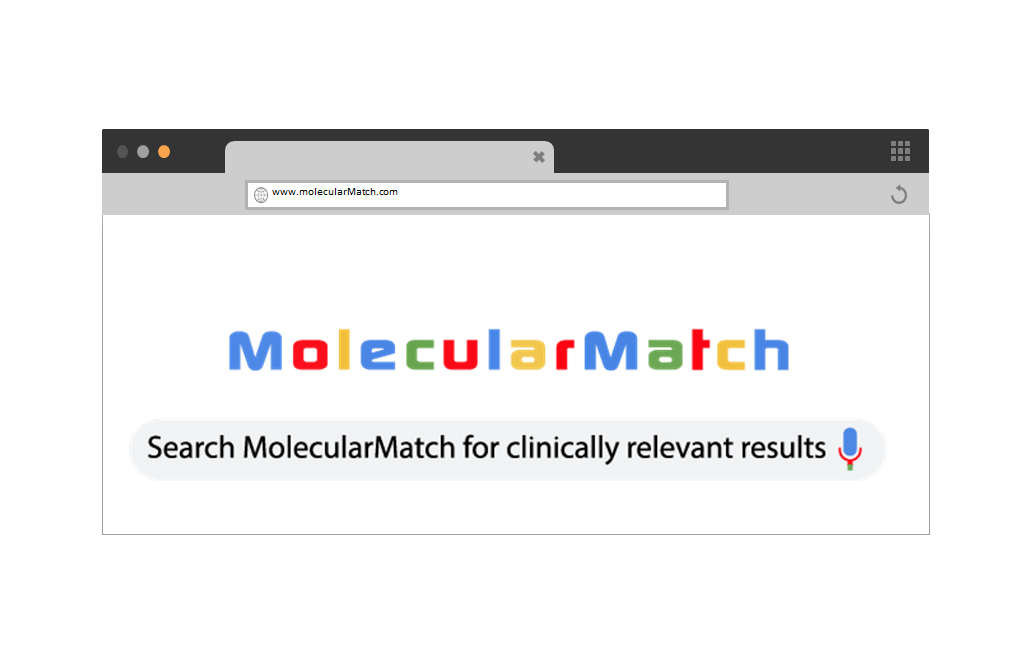
Search from our Portal or via our API
Google-style Search Bar
MolecularMatch provides the most comprehensive Clinical Search available, with features including auto-suggest search terms to deliver a “Google-style” search bar either from the MolecularMatch portal or inside your own customer software using our API.
In Practice
 Dynamic ReportingMolecular labs can ensure quality results and lower costs by powering their custom reporting solutions with MolecularMatch. Dynamic Links on lab reports improve the value proposition and offer unique collaboration between labs and their physician clients.
Dynamic ReportingMolecular labs can ensure quality results and lower costs by powering their custom reporting solutions with MolecularMatch. Dynamic Links on lab reports improve the value proposition and offer unique collaboration between labs and their physician clients.- No Software to InstallMolecularMatch is modern, Data-as-a-Service (DaaS) platform hosted on AWS for high-bandwidth usage and global scalability.
- Power your CDS SolutionsThe MolecularMatch data engine was designed to power custom Clinical Decision Support solutions. Software developers love our open API for real-time results.
Cutting Edge Technology
Dynamic Reporting
Extends the life of your reports by months or years, allowing pathologists to reinterpret previous cases based on the newest FDA approved therapeutics and recruiting clinical trials. Physicians can consider adjustments in the course of care based on the latest information, and your brand can stay top-of-mind with your clients
Automated Technology
Automated technology is our differentiator in the market. We provide the most clinically actionable data to users quickly, efficiently and consistently reducing the manually invasive work typically required to analyze this level of data. Trust us to grow with you. When new data becomes available, we can quickly integrate it and make it available to you.
Real Time Data
API integration with the knowledgebase gives you on-demand access to the most clinically relevant information by allowing you to conduct customized searches. Through extensive engineering, we make sure our network is highly performant and reliable for web-scale applications.
Natural Language Processing
Our Natural Language Processing technology has been specifically designed to extract clinical and genomic meaning from text. We simplify the challenge of entity recognition in the midst of a multitude of clinical and medical nomenclatures and genomic notations. Our entity extraction technology identifies the terms that matter.
Weekly Updates
Clinical Trial and Publication content is acquired, expertly reviewed and released on a weekly basis. Our International Clinical Trial content is sourced from world wide registries and transformed into a single uniform data format. Our publications include conference abstracts in addition to published articles, transformed into a single uniform data format.
Thorough Coverage
Our Comprehensive knowledge base encompasses public and proprietary datasets that connect you with the largest set of actionable information, eliminating gaps in coverage. Continuous monitoring of the changing landscape of precision medicine ensures that you can maintain the highest standards for clinical recommendations.